AI agents have quickly become the next big thing in the AI space. These intelligent systems are now being built into everything from customer support to data analysis – and they’re only getting smarter. Gartner predicts that by 2028, 33% of enterprise software will include agentic AI, up from less than 1% in 2024.
However, the current reality of AI agents isn’t exactly the same as the potential of AI agents. Even though these systems can automate tasks and make decisions, they don’t always get it right. They might miss context, misunderstand nuance, or make mistakes that a human would easily catch.
You can think of AI agents like students – they can learn fast and take on a lot, but they still need teachers to check their work, give feedback, and help them improve. That’s why humans are key to the successful implementation of agentic AI. AI agent evaluation can flag potential issues, since it’s human reviewers who understand the subtle context, edge cases, and real-world impact.
In fact, if you analyze any system using an AI agent today, you’ll find there’s almost always a user feedback loop built in. This is because real-world inputs are essential to helping these agents learn, adapt, and improve over time.
As a spokesperson from Anthropic put it, AI today is more about working with people (57% augmentation) than replacing them (43% automation). Human input isn’t just helpful, it’s foundational. In this article, we’ll explore how human-in-the-loop automation helps make AI more trustworthy by adding human judgment into the agent evaluation process.
An effective AI agent doesn’t just get the job done – it’s one that does it accurately, clearly, and in a way that makes sense in the real world. These smart systems are now being adopted in various industries, from content creation to software testing.
For example, Zendesk, a customer service software company, has introduced AI agents to handle customer support chats, learning from past conversations to get better over time. Similarly, Microsoft’s Analyst that comes with Microsoft 365 Copilot can look at raw data, write simple code, and turn insights into clear reports as though it’s a virtual data analyst on your team. Meanwhile, even in education, Khan Academy, a non-profit educational organization, is using AI to help students learn by giving them a personalized tutor experience.
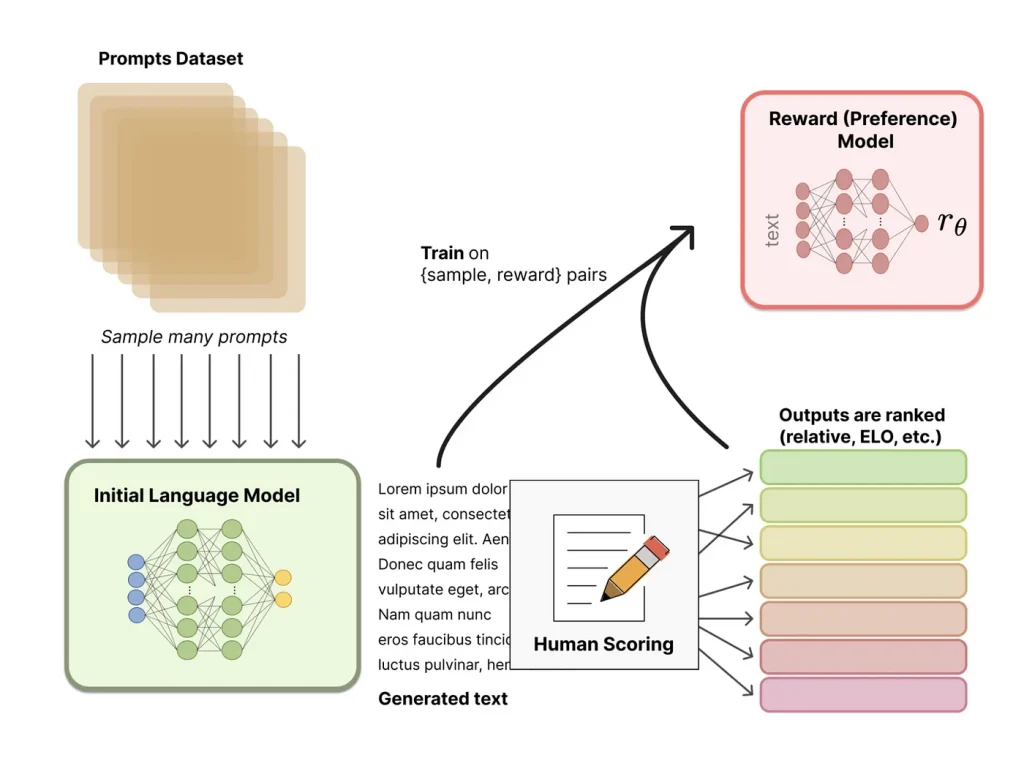
Under the hood of many of these agents is a method called Reinforcement Learning from Human Feedback (RLHF) – simply put, real people guide the AI model by telling it what works and what doesn’t. Companies like OpenAI are using this approach to improve their models.
Since AI agents can make mistakes or misunderstand contextual clues, human-in-the-loop automation and regular agent evaluation are key. Here’s a closer look at some of the challenges AI agents face:
That’s why robust validation methods are so important. Human reviewers help catch these issues before they reach the end user. In high-risk settings, this human-in-the-loop approach isn’t just helpful – it’s necessary to make sure AI agents stay accurate, fair, and aligned with real-world needs.
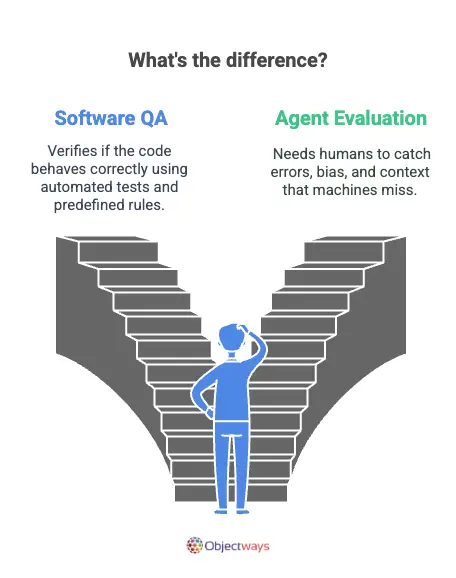
Quality assurance (QA) in software development is a common concept – teams run tests, catch bugs, and make sure everything works before shipping a product. But when it comes to AI agents, quality assurance looks a bit different. Instead of just checking code, we’re validating whether the AI’s responses are accurate, unbiased, relevant, and make sense in context.
So, why is this so different from typical software testing? Because AI agents don’t follow a fixed set of instructions, they generate outputs based on patterns, probabilities, and past data. That means its responses can shift depending on how it’s prompted or what it’s trained on. Automated tests can’t catch things like subtle bias, misleading tone, or logical gaps. These are issues that only human judgment can reliably catch.
Without proper validation, AI agents risk spreading misinformation, making poor decisions, or delivering confusing or harmful outputs. Over time, this can lead to operational failures and a serious loss of user trust. Humans in the loop can help check outputs, provide feedback, and ensure AI agents are working as intended.
Now that we’ve explored why AI agent evaluation is so important, let’s take a look at how it works.
Evaluating an AI agent involves combining structured criteria with human insight to make sure agents are improving over time and can be trusted in real-world applications. The evaluation process typically starts with an initial assessment, where a reviewer checks whether the AI’s output is generally relevant and coherent.
Next, the response is compared against internal quality benchmarks or industry standards, looking at tone, factual accuracy, and structure. Finally, reviewers provide detailed feedback, flagging specific issues and offering suggestions for improvement. This human feedback loop is a critical part of helping AI agents learn from edge cases and continually refine their performance.
Here are some of the core criteria human reviewers use when evaluating AI agent outputs:
Let’s consider a jacket that is listed on an e-commerce site as water-resistant, designed for light rain but not fully waterproof. There is an AI agent responsible for customer support and answering product questions in real time on this site.
A customer asks the AI agent, “Is this jacket waterproof?” The AI agent responds confidently, “Yes, it’s great for all weather and will keep you dry.”
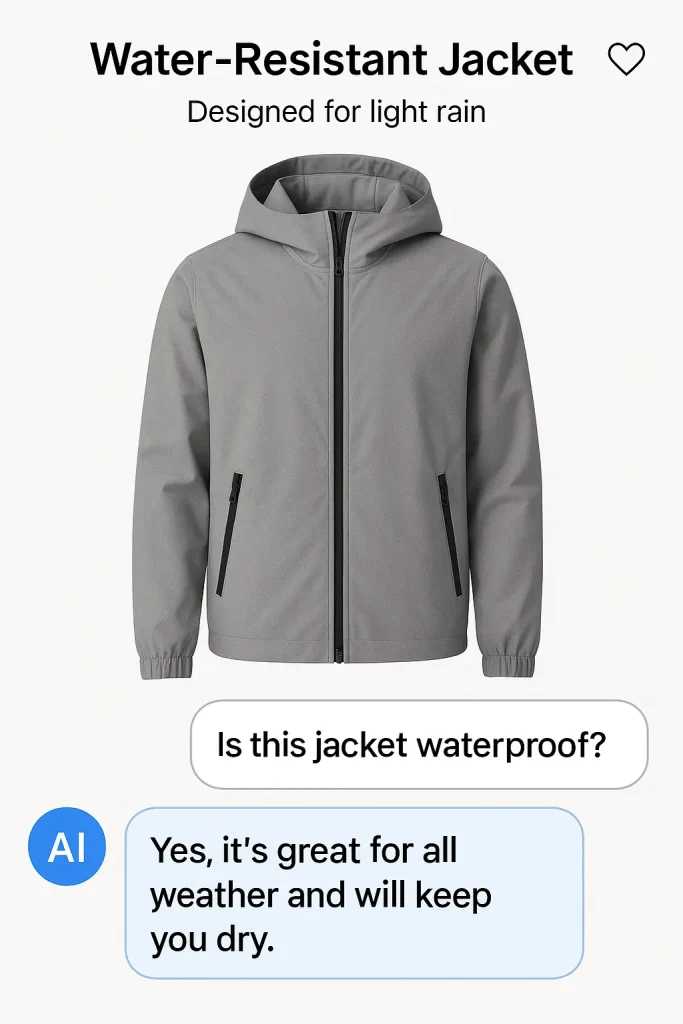
While the answer sounds helpful, it’s misleading. The product isn’t suitable for heavy rain, and this kind of overstatement could lead to unhappy customers or returns. An automated test might approve the response because it matches product keywords, but a human reviewer would catch the inaccuracy, flag the tone, and suggest a correction like, “It’s water-resistant – ideal for light rain but not fully waterproof.”
This is a simple example, but the same concept applies to higher-stakes use cases, like an AI agent assisting a developer with code. A suggestion that seems correct might introduce a subtle bug, security flaw, or performance issue – something a human would be far more likely to notice.
Evaluating one AI agent is simple enough, but doing it at scale – across thousands of outputs, tasks, or users – requires a structured system. That’s where dedicated tools and platforms come in handy. They help streamline the human-in-the-loop process, support large-scale review efforts, and ensure consistency in how agent performance is measured and improved.
Platforms like TensorAct Studio are built specifically for this purpose. With built-in features for assigning, tracking, and scoring evaluations, TensorAct makes large-scale human review both efficient and repeatable.

TensorAct also supports active learning workflows, where models work alongside human evaluators by surfacing only the most uncertain or ambiguous outputs for review. This reduces reviewer load while ensuring feedback is focused where it matters most – on the edge cases and gray areas that need human judgment.
Alongside these tools, QA rubrics play a key role. They provide human reviewers with structured criteria, like accuracy, relevance, clarity, and consistency, so that feedback is consistent and aligned with the use case.
Together, these tools form the backbone of reliable, scalable AI agent evaluation – blending automation with human insight to create smarter, safer systems.
Here are some of the key benefits of human-in-the-loop agent evaluation:
AI agents are getting more advanced, but they still need human oversight to make sure their responses are accurate, fair, and make sense in the real world. Human-in-the-loop AI agent evaluation helps catch things AI models might miss, like subtle mistakes, confusing tones, or biased answers. With tools like TensorAct and clear review guidelines, it’s easier to scale this process effectively.
At Objectways, we help teams do just that by providing reliable human-in-the-loop support. If you’re looking to build AI solutions, book a call with our team today and see how we can build smarter, more efficient innovations together.

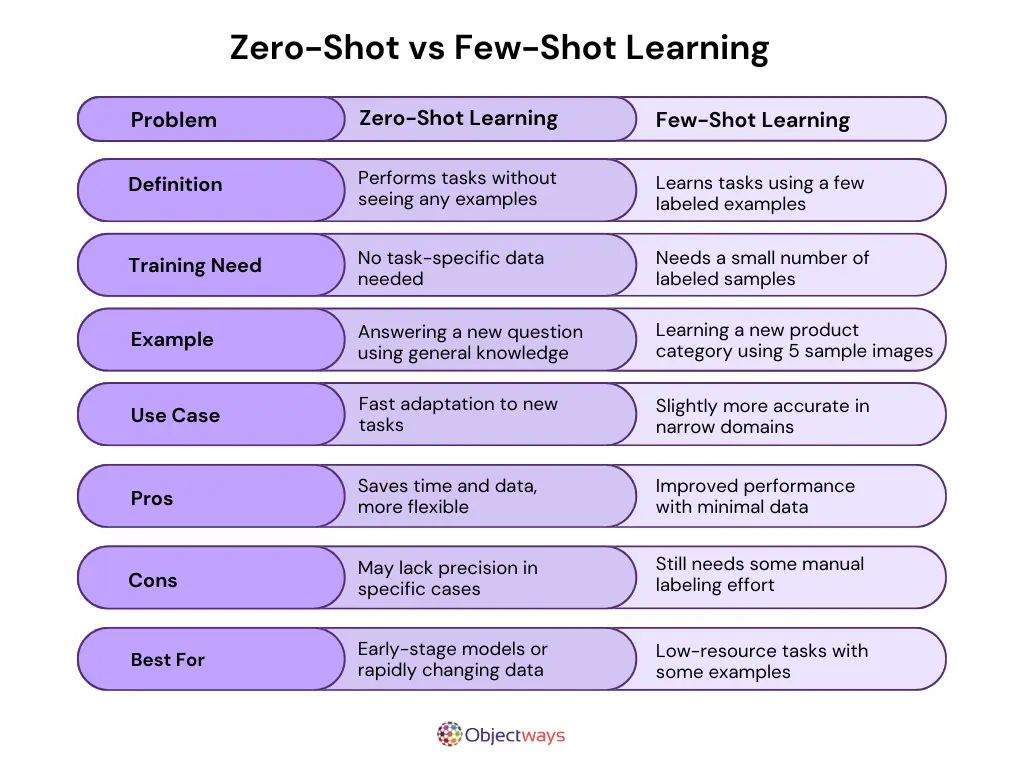
As humans, we often learn new tasks by building on skills we already have. If you can ride a bicycle, picking up how to ride...
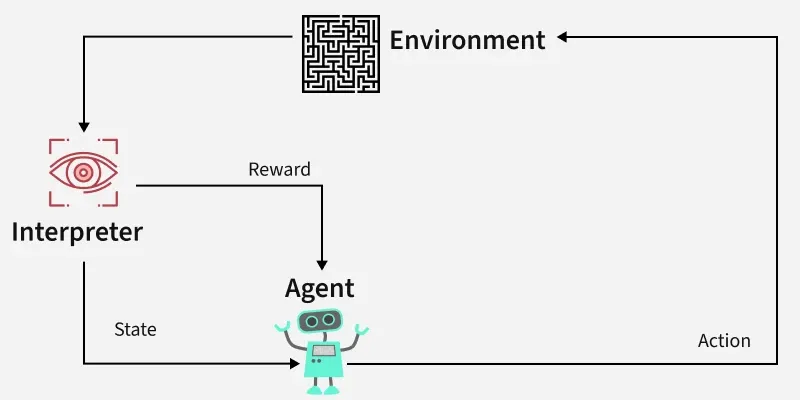
Creating a chatbot goes beyond just making it feel like a real conversation. It’s about truly understanding what users need and helping them find the...
