One of the most important parts of any AI project, that often gets overlooked, is preparing the data needed to train a model. This process usually starts with data collection and sourcing – simply put, finding the right data from reliable sources or creating it when necessary.
Then comes data labeling, which can be done manually or by using data labeling tools and platforms. Labels or annotated data are essential because they directly impact AI model performance. It’s like building a house on a shaky foundation. If the training data isn’t reliable and well-labeled, everything that comes after is at risk of falling apart.
That’s why these early steps often end up being time-consuming. In fact, a 2020 report found that over 50% of the time spent on machine learning projects goes into labeling and cleaning data – more than the time spent on building or training models.
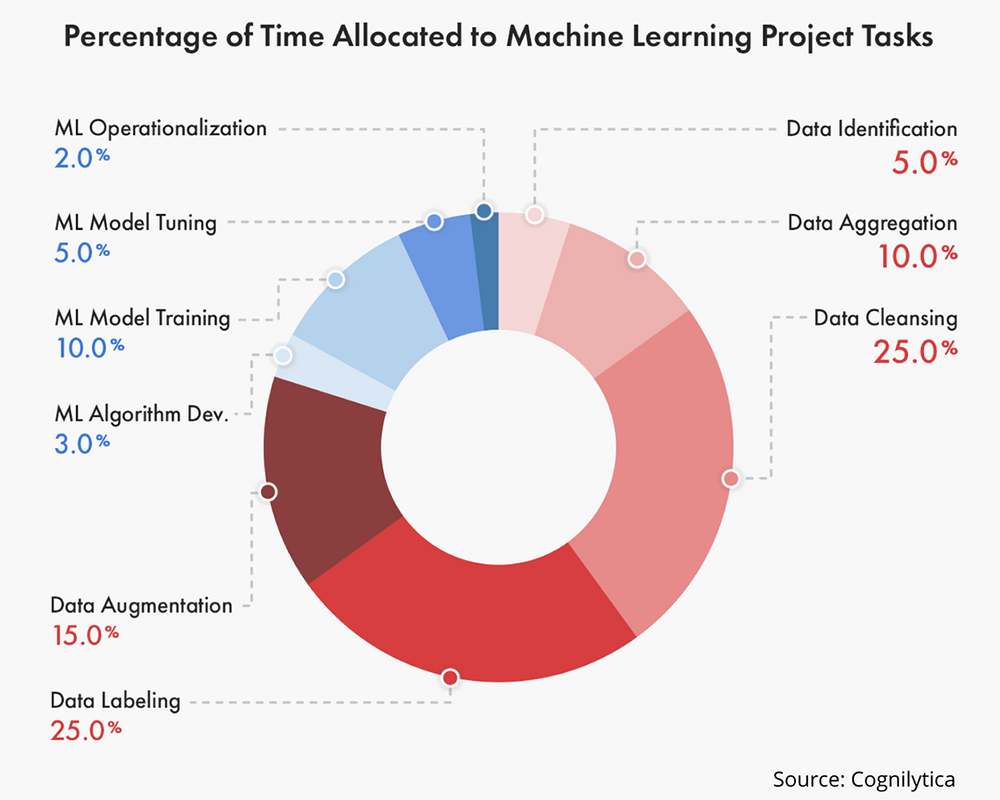
To make that time worthwhile, it’s important to focus on the quality of the labels, not just the quantity of the data. Effective labeling relies on accurate, consistent, and clear labels across all types of data.
Previously, we have explored how data integrity forms the foundation of successful AI solutions. In this article, we will take a closer look at how to evaluate the quality of labeled data. We will walk through key metrics, helpful tools, and best practices to help you build more accurate and reliable AI systems.
Data labeling is the process of adding tags or annotations to raw data so that machines can understand it. This can look like using data labeling tools to draw bounding boxes around objects in images, assign categories to text, or mark key sections of audio. These labels enable AI models such as computer vision models and large language models (LLMs) to learn from examples during model training.

The model learns from labeled examples like a baby learning to speak – by repeatedly observing patterns in context, it gradually builds an understanding of how to associate inputs with the correct outputs. An AI model can then use that knowledge to make predictions on new, unseen data.
For model training to work well, it must be fueled by accurate and high-quality data. If the labels are wrong, the model learns incorrect information. This can lead to errors and poor performance later in the project. That’s why the saying “garbage in, garbage out” is so relevant – if you feed the model bad data, you can’t expect good results.
Also, consistency is just as important as accuracy. When similar data is labeled in different ways, the model receives mixed signals. This can make it harder for the model to learn and reduce its reliability. Even small mistakes in labeling can add up, leading to confusion during training and weaker results in production.
Now that we have a better understanding of the need for quality data labels, let’s look at how to check if those labels are actually good enough for training AI models. Using the right metrics, and the help of data labeling tools, can make it easier to evaluate the accuracy, consistency, and overall quality of labeled data.
Accuracy is a common metric used to check the quality of labeled data. It tells you how many labels are correct out of the total number of labels.
For example, if you have a set of 1,000 images and 950 are labeled correctly, the accuracy is 95%. Here is a look at the formula:
Accuracy = (Correct Labels ÷ Total Labels) × 100
Accuracy works well when the data is balanced. This means each category, like “cat,” “dog,” or “bird,” has about the same number of examples. In that case, accuracy gives a clear picture of how well the labeling was done.
However, accuracy can be misleading when the data is imbalanced, with one class dominating. For instance, if 900 out of 1,000 images are of cats, someone could label everything as “cat” and still get 90% accuracy. That number might look good, but the incorrect labels for dogs and birds make the dataset less useful for training a model.
In real-world projects, accuracy is often used to evaluate batches of labeled data and to track progress over time. For example, if accuracy improves from 85% to 92%, it suggests the labeling process is becoming more consistent and reliable.
Accuracy tells us how many labels are correct, but it doesn’t showcase whether different annotators are labeling data in the same way. To check consistency between labelers, teams often look at inter-annotator agreement, also known as inter-rater reliability. It gives insights into whether everyone is annotating data in a similar and reliable way.
When agreement is high, it usually means the task is clear and the instructions are easy to follow. If agreement is low, the data might be difficult to label, or the guidelines may need to be improved.
When there are two labelers, a common way to measure agreement is Cohen’s Kappa. You can think of it as two teachers grading the same test. If they often give the same score, that shows strong agreement. This method also considers how often agreement could happen just by chance.
For more than two labelers, Fleiss’ Kappa is often used. It works more like a panel of judges. If most of them give similar scores, it shows good consistency. If their scores vary quite a lot, there may be confusion about the task.
We’ve seen how accuracy can give a general sense of performance, but it doesn’t tell the whole story – especially when dealing with imbalanced datasets. For example, if you’re labeling data into categories where one class dominates, accuracy might appear high even if many important cases are mislabeled or missed.
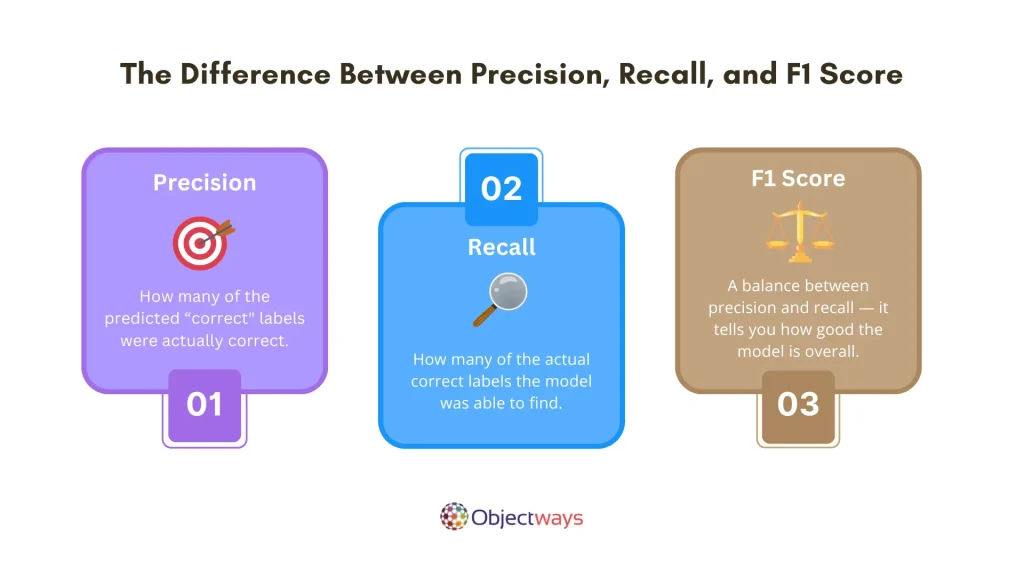
That’s why it’s important to use other metrics, like precision, recall, and F1 score, to evaluate the quality of labeled data itself, not just the model that uses it. These metrics help determine whether the labels are not only correct, but also consistent and comprehensive across the dataset.
Here’s a quick look at how they apply to evaluating labeled data:
Regular quality assurance checks help ensure that labeled data remains accurate, consistent, and usable for model training. These checks are important for catching mistakes early, before they affect the performance of the model.
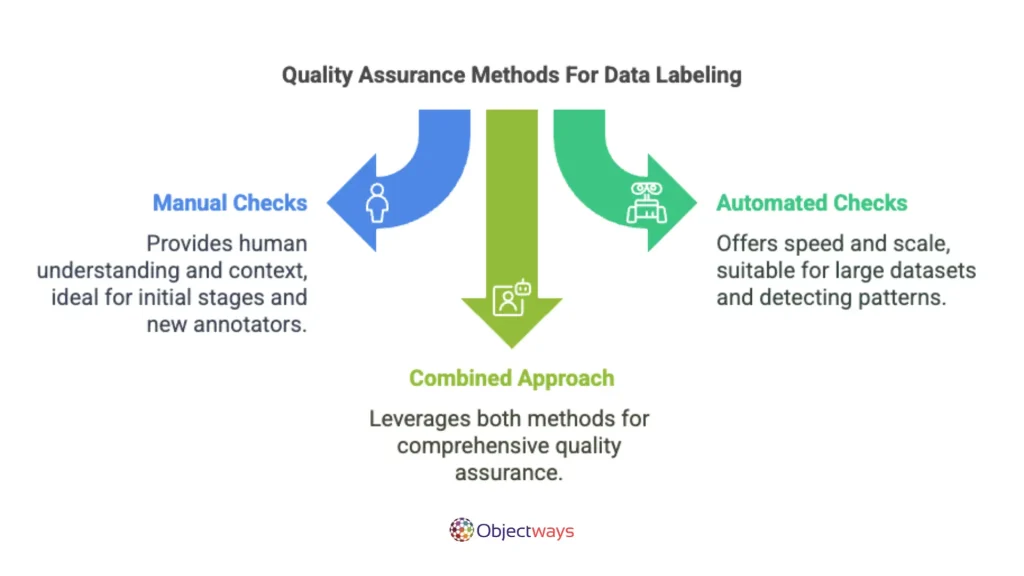
A common method used for this is manual spot checking. A reviewer looks through a small sample of the labeled data to find errors, unclear annotations, or anything that goes against the guidelines. This type of review is helpful for identifying obvious issues and giving quick feedback.
Manual reviews are especially useful at the beginning of a project or when working with new annotators. They make it possible to set clear expectations and guide labelers in the right direction from the start.
Meanwhile, automated reviews take a different approach. They use software or rule-based systems to scan large amounts of data quickly. These tools can detect missing labels, flag unusual patterns, or highlight entries that do not follow an expected format.
Each quality assurance method has its own strengths. Manual checks provide human understanding and context, while automated checks offer speed and scale. When both are used together as part of a regular workflow, they can help maintain high labeling quality across an entire project.
Data labeling tools and platforms can make it easier to manage, review, and improve the quality of labeled data throughout the entire process – not just during the annotation step. With the right features, these tools help teams work more efficiently, reduce errors, and maintain high standards at scale.
Here are a few key capabilities to look for when selecting data labeling tools and platforms to use:
For instance, data labeling platforms like TensorAct Studio are built to support not just the labeling task, but the entire process of measuring and managing quality from start to finish.
TensorAct Studio includes built-in dashboards that track important metrics such as accuracy, inter-annotator agreement, and review completion rates. These features help spot issues early and improve labeling performance over time.
Also, TensorAct Studio makes it easier to manage the labeling process by supporting review steps with clear roles for each team member. This helps reduce mistakes and keeps labeling consistent. Reviewers can follow built-in guidelines made for each project, so quality checks are done the same way every time.
On top of this, the platform also uses active learning to find data that the model is unsure about and sends it to a human for review. This guarantees that time and effort are spent on the things that matter most.
As AI continues to evolve, the way data labeling is done is also changing. Here are some recent trends that are enhancing the speed, accuracy, and overall quality of data labeling:
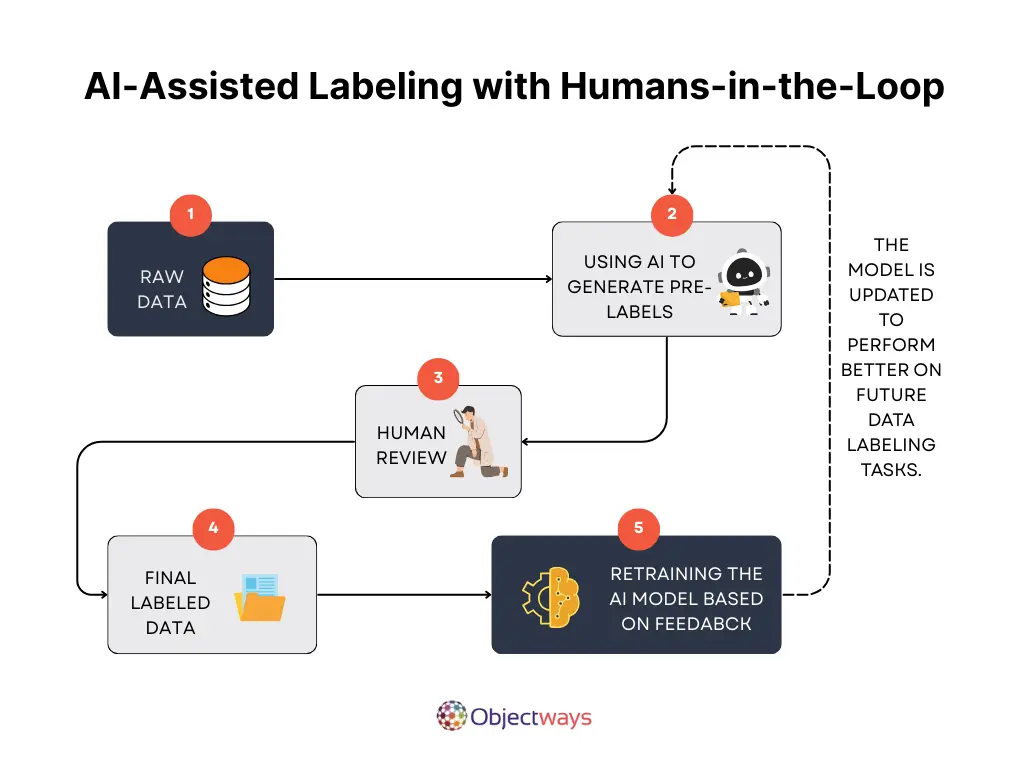
Using the right tools and staying on top of trends is crucial, but good labeling starts with following the right practices. Here are some best practices to keep in mind when preparing data for your AI project:
Following all of these best practices can be challenging – and that’s where experts can step in to help. If you’re looking to implement an AI solution, reach out to Objectways. We specialize in building AI innovations, data labeling services, and data sourcing services.
Data labeling plays a key role in how well an AI model learns and performs. When labels are accurate and consistent, the model can better understand the data – leading to more reliable results in real-world applications.
A data labeling platform like TensorAct Studio supports this entire process with features like real-time quality tracking, review workflows, and active learning. It helps make sure your labeled data is high-quality from start to finish.
At Objectways, we provide the tools and expert support you need to build a strong foundation for your AI projects. Ready to take the next step? Get in touch with us today.

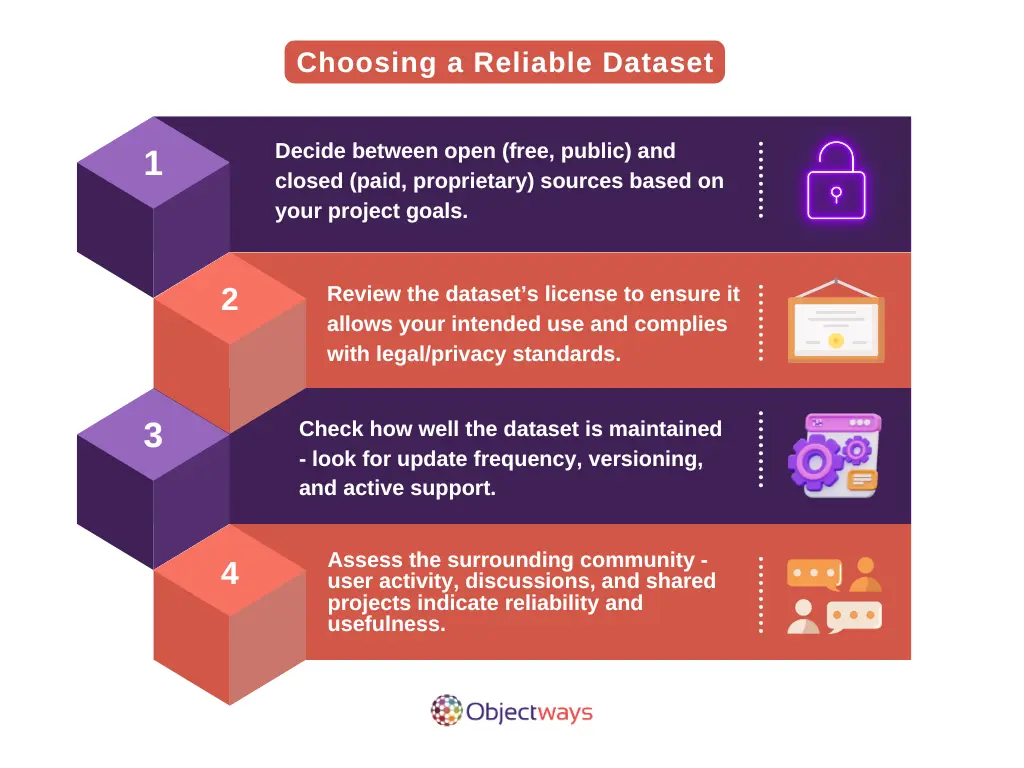
Choosing the right dataset is one of the most important steps in building an object detection model that performs well. Just like you need a...
Choosing a data labeling tool for your AI project is a lot like picking the right equipment for a construction job. You wouldn’t rely on light-duty tools...
