The introduction of LLMs (large language models), such as GPT-3.5 Turbo and GPT-4, has made a huge impact on AI applications. Their ability to generate human-like responses and handle complex tasks has made LLMs an important tool in various AI solutions.
However, while LLMs are robust at handling difficult tasks, they come with certain challenges. Due to their large size and intensive development needs, these models require substantial computational power and advanced hardware for deployment. Also, the energy consumption and latency related to processing can be problematic in resource-constrained environments.
To tackle these challenges, LLM distillation, a model distillation technique that reduces model size while preserving performance, was introduced. In this article, we’ll explore what LLM distillation is, how it works, and why it matters in today’s AI market space.
LLM distillation is a technique used to compress large language models while maintaining their accuracy and efficiency. It involves creating a lightweight version of a powerful LLM that uses fewer resources. Think of it as carrying a pocket-sized dictionary instead of a heavy hardcover one; you still have access to all the words and meanings, but in a more convenient and portable form.
Also, the concept of LLM distillation is part of a broader AI technique known as model distillation. Model distillation is focused on transferring knowledge from a large, complex model to a simpler, smaller one. This process helps businesses reduce computational cost, improve inference speed, and make models more practical for real-world applications.
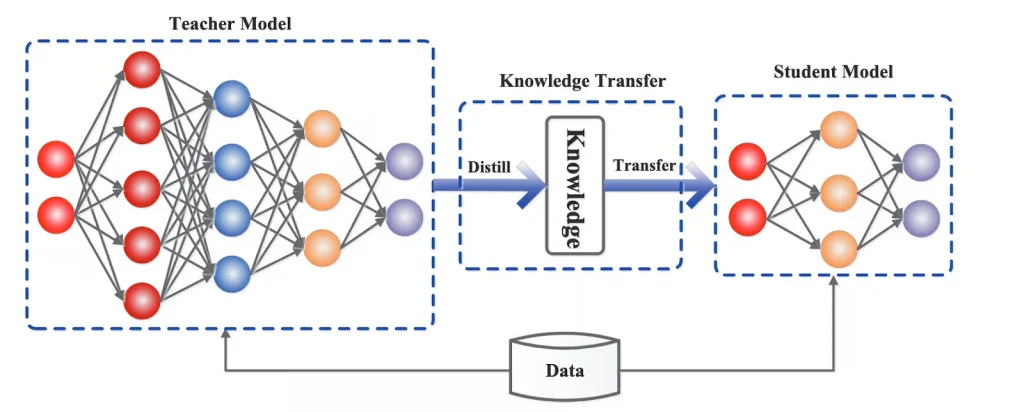
LLM distillation follows a teacher-student framework, where knowledge is transferred from a teacher model (a large LLM) to a student model (a smaller, distilled version). Let’s take a closer look at this framework.
The teacher-student framework works like creating a scaled-down version of a statue. Picture a master sculptor crafting a full-sized statue (teacher model), which requires a large amount of raw materials (training data), a skilled workforce (training process), and significant time.
Now, imagine creating a miniature model (the student model) of this statue for commercial purposes. Instead of starting from scratch, you would analyze the actual statue and take note of the specialized curves and other dimensions.
By studying the master’s creation, you can create more miniatures with fewer resources that can be used for different purposes, like collectibles, educational displays, and set properties in movies.
LLM distillation involves several key techniques designed to effectively transfer knowledge from the teacher model to the student model. Let’s see some of the popular techniques used in LLM distillation.
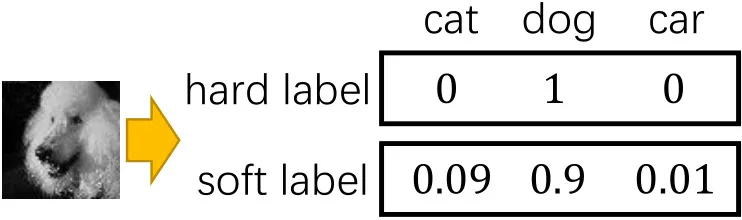
Soft label training is a method where a smaller model (student model) learns from a larger, more powerful model (teacher model) by receiving more detailed feedback. Instead of giving simple ‘right or wrong’ answers, like labeling an image as just a ‘cat’ or ‘dog,’ the teacher model provides probabilities that show its level of confidence.
For example, instead of saying an image is definitely a cat, it might say ‘cat: 80%, tiger: 10%, leopard: 10%.’ This means the model is mostly sure it’s a cat but sees some similarities to a tiger or leopard. By learning from these probabilities, the student model gains a deeper understanding, helping it make better decisions and generalize more effectively to new situations.
Meanwhile, in the feature-based technique, the student model learns from the teacher model’s internal architecture. Simply put, instead of only copying the teacher’s answers, the student looks at the teacher’s internal steps – how it recognizes patterns and makes decisions at different stages.
The student model can understand and replicate the teacher model’s thought process at multiple levels, from simple patterns to more complex features. By learning in this way, the student model gains a deeper understanding of the data, allowing it to perform better and make more accurate predictions.
Another important concept in knowledge transfer is attention mapping. This technique helps the student model learn which parts of the input data are most important in a way similar to the teacher model.
The teacher model doesn’t treat all information equally – it focuses more on certain words, patterns, or features that are crucial for understanding the data. By analyzing how the teacher distributes attention, the student model learns which elements to prioritize and how different pieces of information are connected. This lets the student model process complex language, identify meaningful patterns, and handle challenging tasks with greater accuracy.
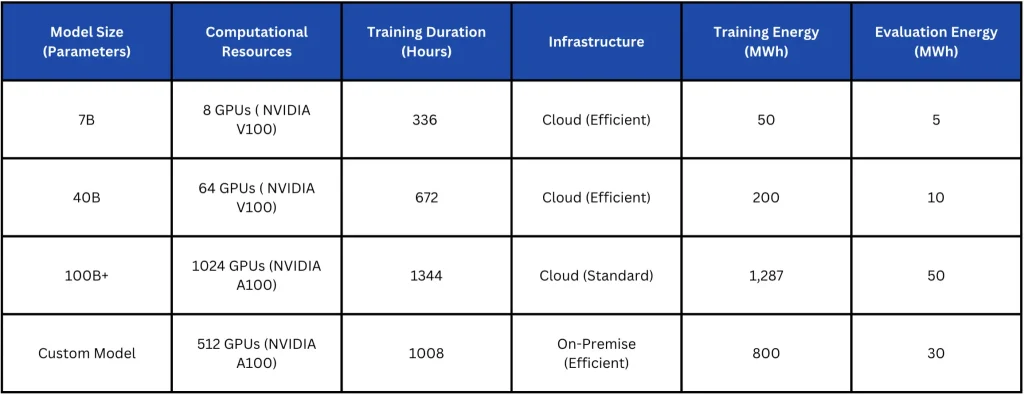
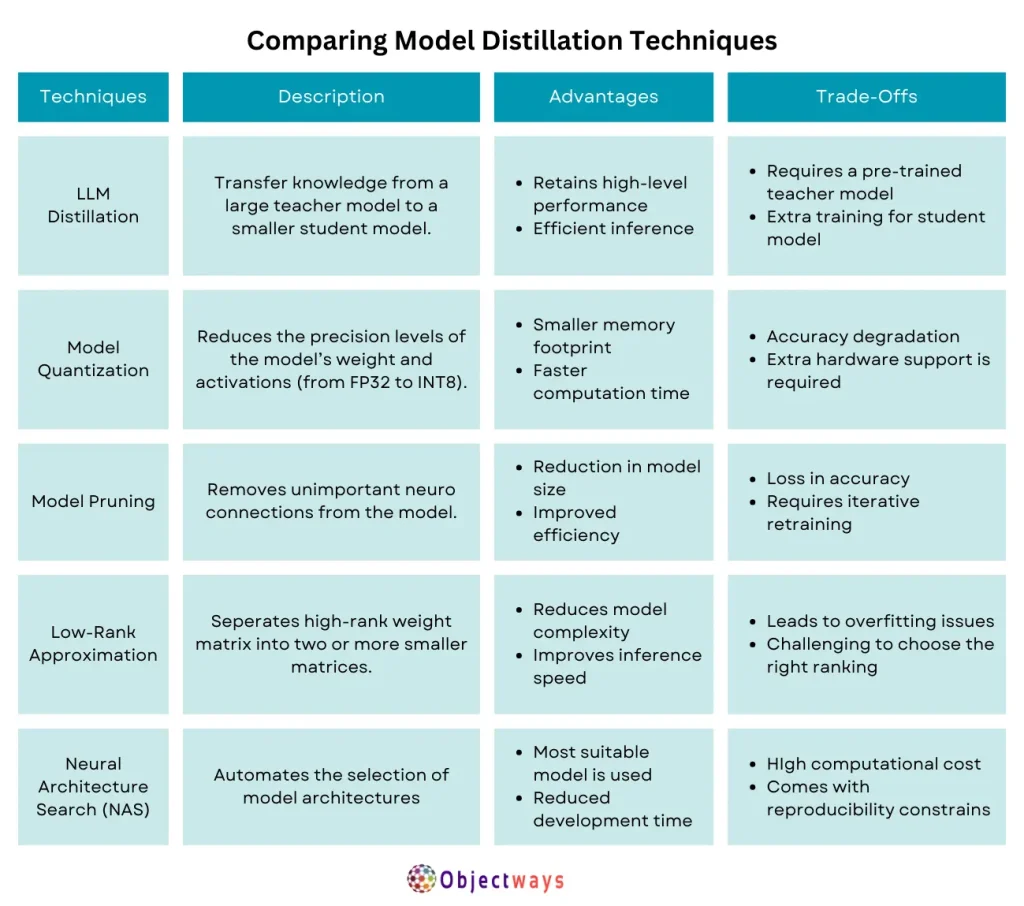
To get a better idea of why LLM distillation is a great option, it’s important to compare it with other model optimization techniques. Various methods, such as model quantization, pruning, and low-rank approximation, aim to reduce model size and improve efficiency.
However, each approach comes with its own strengths and limitations. Some techniques focus on reducing memory usage or computation time, while others prioritize maintaining accuracy or improving inference speed. The table below provides a detailed comparison of different model distillation techniques, helping to understand their benefits, trade-offs, and overall impact on AI performance.
You might be wondering if distilled LLMs are really necessary. Here are some advantages of using distilled LLMs over full-scale models that highlight their importance:
LLM ranking is a standardized evaluation process based on key performance metrics that determines the model’s accuracy and compatibility for practical applications. As LLM models differ in size, speed, and efficiency, this standardization helps organizations choose the most suitable model for their specific needs.
You can compare LLM ranking to choosing the best restaurant in town based on different factors like food quality, service, price, and ambiance, even though the restaurants may serve different cuisines.
This ranking process is particularly important when evaluating distilled LLMs, as it helps measure how well they retain the capabilities of their larger counterparts while offering improvements in efficiency, speed, and sustainability.
Several metrics are used to evaluate and compare LLMs. Each metric highlights a specific aspect of the model’s performance.
Here are some crucial metrics and their role in the LLM ranking process:
Distilled LLMs are used in various applications across different sectors. Here’s a quick glimpse of where they are being used commonly:
Now that we’ve looked at some general applications, let’s dive into a case study to get better insights into how a distilled LLM can be implemented into a practical AI solution.
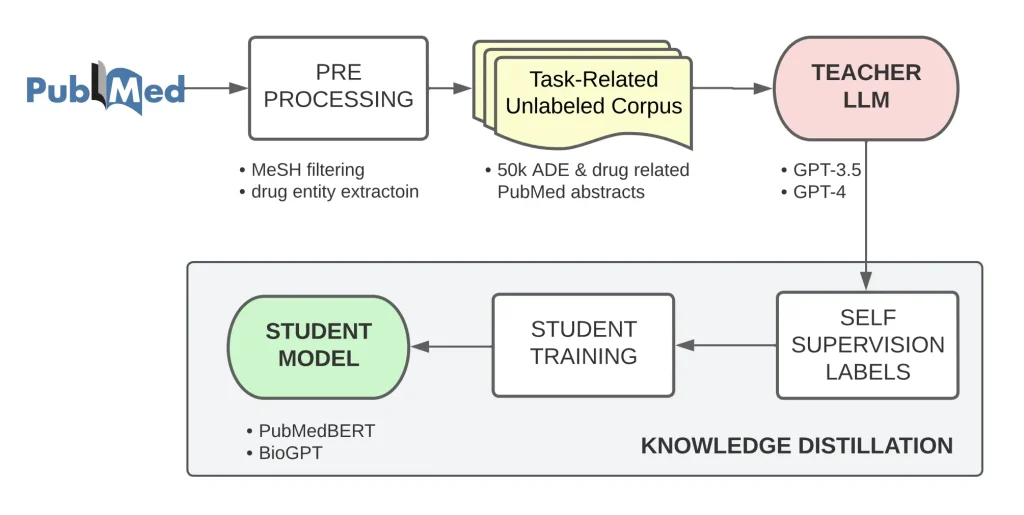
Extracting biomedical information is crucial in healthcare and pharmaceutical research. It helps identify important insights, such as drug interactions, disease patterns, and treatment outcomes. However, this process can be slow and requires significant computational resources.
For example, in adverse drug events (ADEs) – situations where medications cause unexpected negative effects – large language models (LLMs) like GPT-3.5 Turbo and GPT-4 can analyze vast amounts of medical data to detect patterns and potential risks. These models perform well because they can process diverse datasets, including research papers, clinical trial reports, and patient records.
Despite their performance, these LLMs require a lot of computing power, making them expensive and difficult to deploy in real-world medical settings. However, distilled models can improve biomedical knowledge extraction.
In this case, a research team used GPT-3.5 as a teacher model and trained a student model based on PubMedBERT. Using self-supervised learning, they fine-tuned the student model to perform ADE extraction as accurately as high-performance LLMs.
The distilled PubMedBERT model, despite being over 1,000 times smaller than GPT-3.5, outperformed GPT-3.5 in standard ADE extraction evaluations. This success highlights the impact of model distillation in making advanced AI systems more efficient, accessible, and practical for specialized, resource-constrained domains like healthcare and pharmaceutical research.
Looking ahead, emerging trends such as hybrid distillation, synthetic data training, and federated learning are expected to redefine LLM deployment and accessibility. Here’s a closer look at these ideas:
If you’re thinking about using LLMs or distilled LLMs in your business, having the right expertise can make all the difference, and you’re at the right place. At Objectways, we can help you streamline processes, improve efficiency, and tailor AI to your unique needs.
LLM distillation is a game-changer for making large language models more practical and accessible. Transferring knowledge from large, resource-heavy models to smaller, more efficient ones helps overcome challenges like high computational costs, latency, and deployment in real-world applications. As AI advances, new distillation techniques will continue to push the boundaries of efficiency and accessibility.
At Objectways, we specialize in developing customizable AI models with expert data labeling. Book a call with our team today and see how we can build smarter, more efficient AI solutions together.

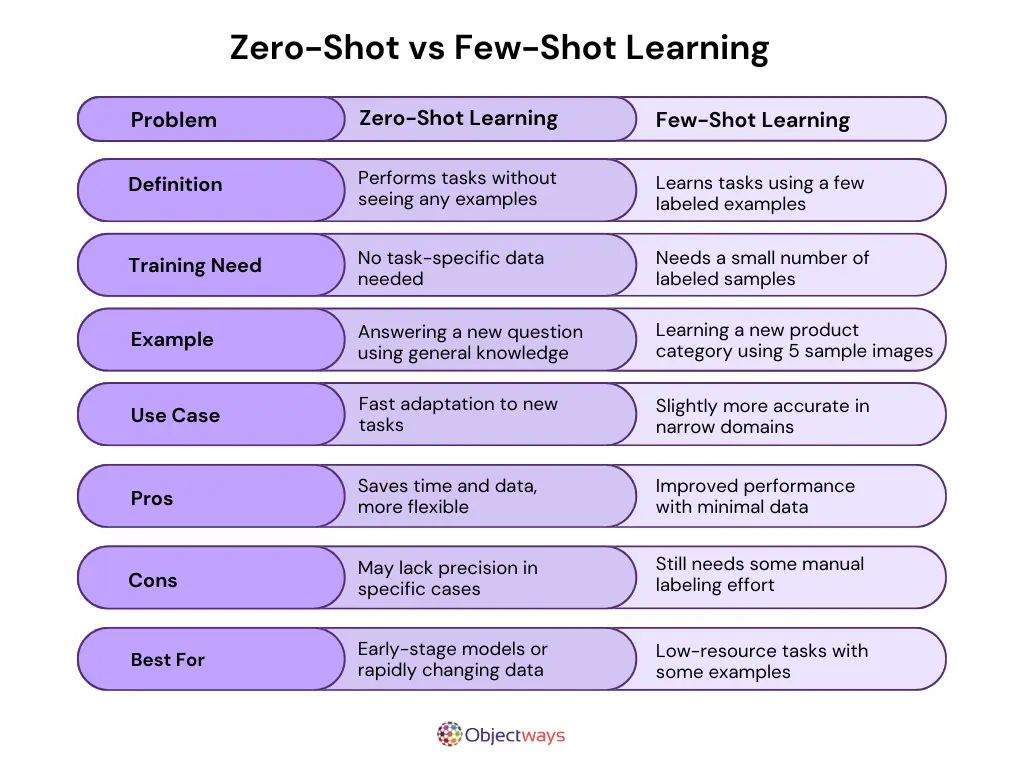
As humans, we often learn new tasks by building on skills we already have. If you can ride a bicycle, picking up how to ride...
Creating a chatbot goes beyond just making it feel like a real conversation. It’s about truly understanding what users need and helping them find the...
