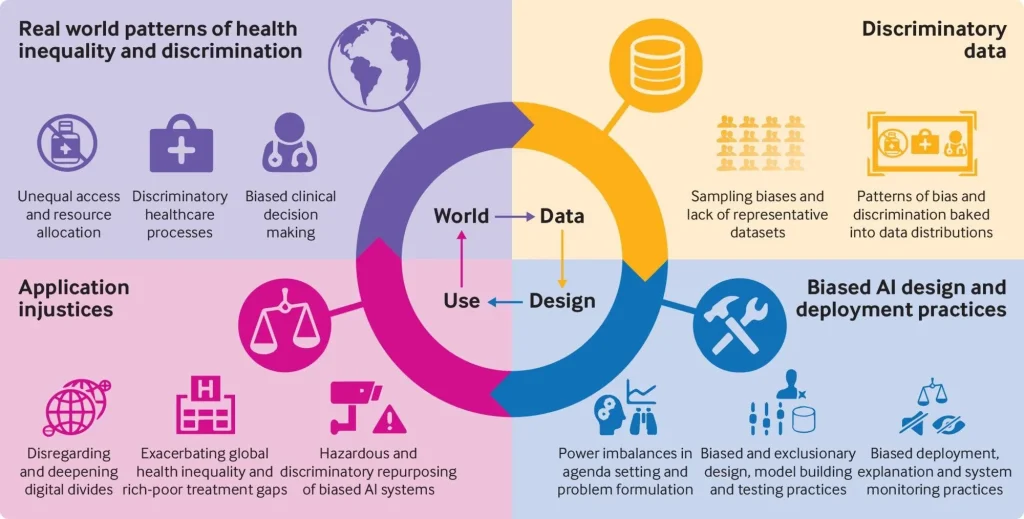
Whether detecting fraud in financial transactions or identifying objects in images, AI models are known for their ability to recognize patterns in data. However, patterns alone don’t tell the whole story.
Unlike humans, who reason and interpret context, AI models rely mostly on statistical correlations. Most AI models don’t truly understand what they see. They just recognize patterns and make predictions based on data. This approach works – until it doesn’t.
When an AI system mistakes coincidence for causation, serious errors can follow, with models learning the wrong lessons from the data they’re given. In fact, up to 38.6% of data AI models are trained on can be biased. This means they often reinforce flawed patterns instead of identifying real causation.
At the heart of this issue is how AI models process information. AI models identify patterns in data rather than forming conceptual connections. They map inputs to outputs based on probabilities – unlike how humans process information. A model trained to identify cats isn’t thinking, “This is a cat.” Instead, it notices that certain features, pointed ears, whiskers, and fur texture, frequently appear in images labeled “cat.”
While this works in most cases, the problem arises when AI models pick up on irrelevant details. The model might mistakenly associate darkness with cats if most cat images in a dataset are taken in dim lighting. This misinterpretation isn’t just theoretical – real-world AI applications have shown similar issues. For example, in medical imaging, an AI model may misdiagnose patients by incorrectly identifying image artifacts as signs of illness. Even advanced AI systems can make mistakes when they ignore crucial context clues.
The “wolf vs. husky” experiment is a well-known example of AI misunderstanding context. In this case, the AI model misinterpreted context by distinguishing between wolves and huskies based on irrelevant features, like the background or snow, rather than the animals themselves.
Since most images of wolves in the dataset featured snowy landscapes, the model associated snow with wolves. As a result, it misclassified huskies in snowy conditions as wolves. Unfortunately, models don’t always learn what we intend. Instead, they pick up patterns from the data, even if those patterns lead to wrong conclusions.

AI models are great at spotting patterns and making predictions based on data. Just like we associate dark clouds with rain, these models find statistical connections between inputs and outcomes. The more high-quality data they process, the better they get at recognizing these patterns. However, unlike humans, who understand that dark clouds don’t cause rain but simply signal its likelihood, AI doesn’t grasp the reasons behind the patterns – it just detects them.
This is where correlation and causation diverge. Correlation is the observation that two variables often appear together, while causation means one directly influences the other. For instance, an AI model analyzing workplace success might find that employees who send shorter emails tend to hold leadership roles. If not carefully trained, the model could mistake correlation for causation, assuming that writing concise emails leads to career advancement rather than recognizing that leadership roles demand efficiency and decision-making skills. The risk lies in AI systems drawing conclusions based purely on patterns rather than genuine cause-and-effect relationships.
Training AI models isn’t just about feeding them lots of data. It involves refining datasets, identifying key features, and ensuring human oversight. This helps the model make meaningful connections instead of relying on shallow patterns. Without these steps, an AI system could reinforce biases, make flawed decisions, or produce statistically accurate results that don’t work in the real world.

Next, let’s look at examples showing how AI models, without understanding context, can make mistakes, ranging from minor errors to serious real-world failures.
AI models used in medical diagnostics may struggle with accuracy across different skin tones. A model trained mainly on lighter skin may misdiagnose conditions on darker skin due to biased training data. The issue isn’t the algorithm itself but the lack of diverse examples in its dataset.
Without inclusive training, the model learns an incomplete version of reality, potentially leading to harmful errors in diagnosis. Ensuring diverse and representative data is key to building reliable medical AI.
An AI system designed to detect fraudulent benefit claims may seem like an efficient tool for preventing misuse. However, when deployed, it could disproportionately flag certain groups – not based on actual fraud patterns, but due to biases in its training data.
For instance, a recent assessment of the UK’s Department for Work and Pensions (DWP) AI system found that it unfairly singled out individuals based on factors like age, disability, and nationality. Instead of identifying genuine fraudulent activity, the model learned to associate specific demographics with risks and lead to unnecessary investigations and undue scrutiny. Ultimately, a system that was meant to uphold fairness in welfare distribution instead reinforced systemic biases.
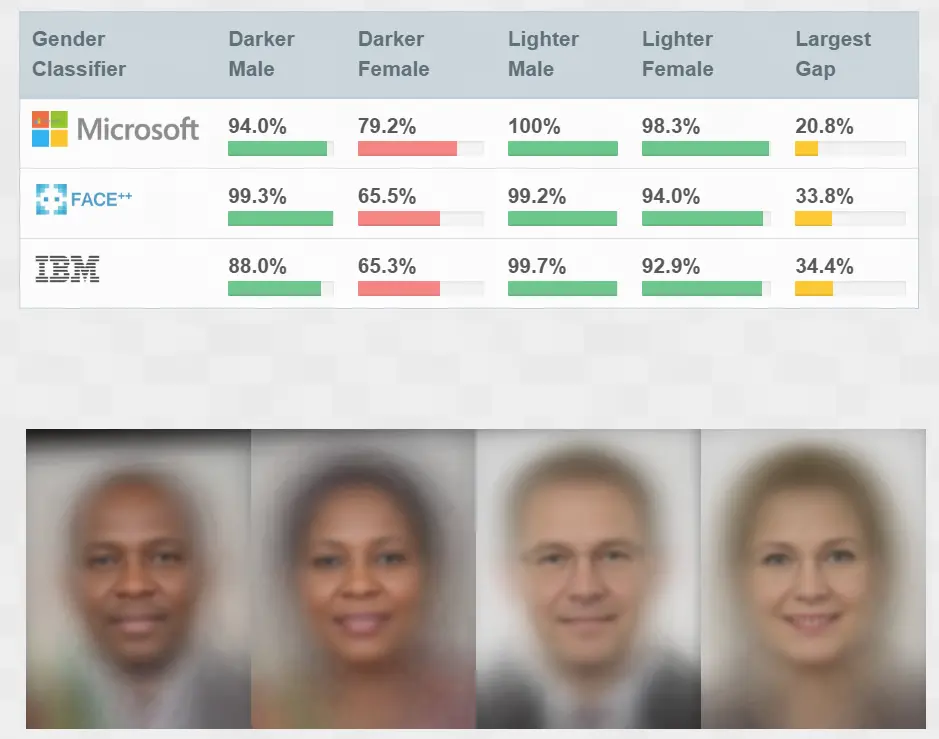
Facial recognition systems promise accuracy, but that accuracy isn’t always universal. Research from the Gender Shades project found that these systems performed well on lighter-skinned men but misclassified darker-skinned women at alarmingly high rates. The problem wasn’t the algorithm itself – it was the data it was trained on.
With datasets skewed toward lighter-skinned individuals, the models failed to recognize diverse faces correctly. Instead of offering unbiased identification, these systems reinforced racial and gender disparities, leading to real-world consequences in law enforcement, hiring, and security screening.
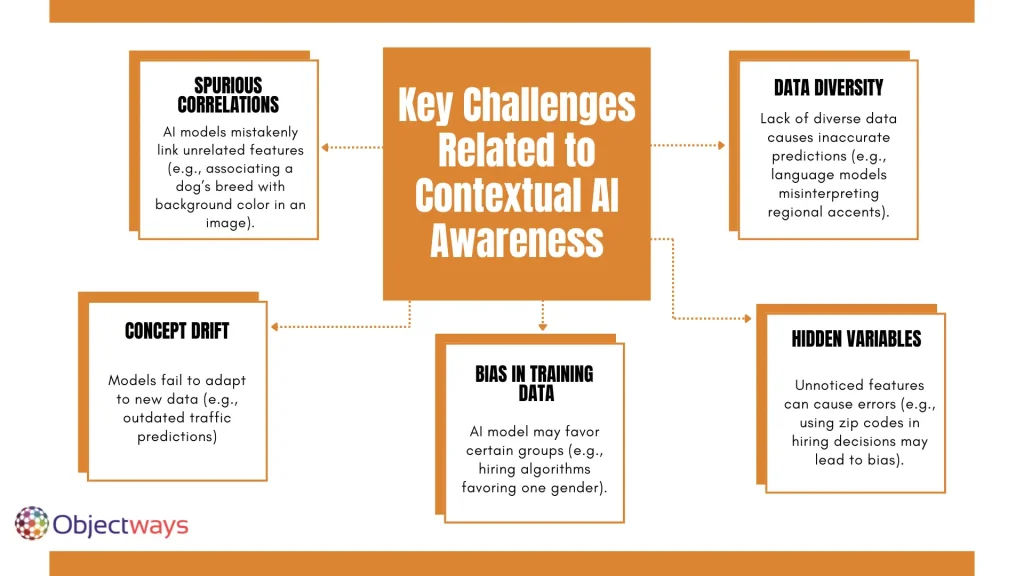
Let’s take a closer look at how AI models can struggle with context, leading to various issues in predictions:
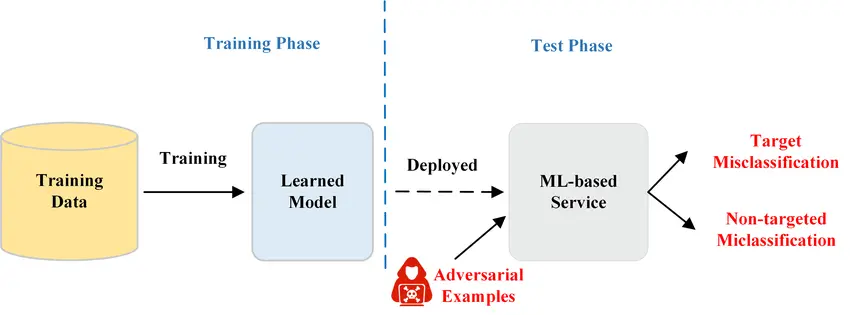
The AI community is actively working on addressing the challenges related to AI systems understanding context. Also, there are specific best practices that can be followed to create more fair and accurate AI innovations. Let’s walk through some of the key factors of context-aware AI training.
If an AI model related to self-driving cars is trained only on sunny daytime roads, it may struggle in foggy or nighttime conditions. AI models need exposure to various environments, lighting, and situations to perform reliably. Without diverse training data, they risk making errors when faced with unfamiliar conditions. Expanding datasets to include different scenarios, along with precise annotations for objects like pedestrians, road signs, and obstacles, helps AI models adapt and function accurately in real-world applications.
AI models can sometimes focus on the wrong details and this can lead to inaccurate results. Human oversight can make sure that they prioritize relevant factors. For example, a hiring algorithm might rank candidates based on resume formatting rather than qualifications. If a well-qualified applicant uses an unconventional layout, the system might overlook them. Human experts can step in to correct such biases. AI engineers can reinforce the model to evaluate skills and experience instead of superficial elements.
Adversarial training helps make AI smarter by throwing it into tough situations, forcing it to adapt. Think of it like training an athlete by making them run on uneven ground so they’re ready for any terrain. For example, in facial recognition, developers might slightly blur an image or change the lighting to see if the AI can still recognize the person. If it struggles, they tweak the system until it gets better at handling real-world unpredictability. This way, the AI learns to spot patterns even when things aren’t perfect, reducing mistakes.
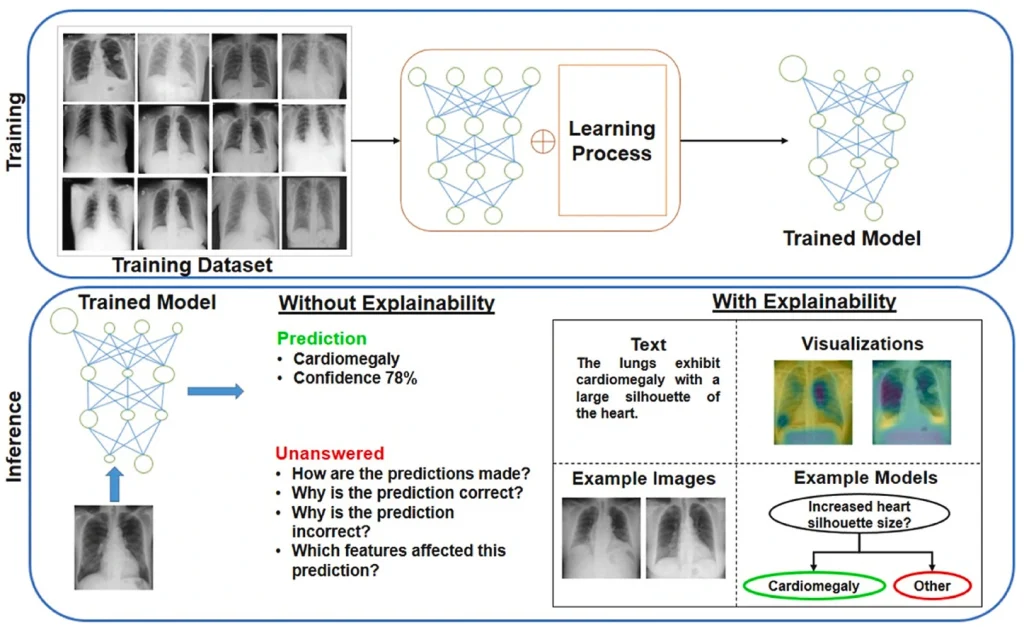
Explainable AI is a set of methods and processes that help humans understand and trust the outputs of complex AI models. It aims to make AI decisions transparent and interpretable so that users can understand the reasoning behind predictions.
With respect to context-aware AI, XAI techniques like SHAP, LIME, and Saliency Maps help make AI decisions more transparent and understandable. Here’s a closer look at these techniques:
These techniques help make AI more transparent, accountable, and reliable, which is especially crucial in sensitive fields like healthcare, where understanding AI decisions can directly impact patient care.
AI models need periodic updates to remain accurate and adapt to evolving data patterns. Without regular retraining, models risk making outdated predictions because they may not account for new trends or behaviors. For instance, a model predicting consumer behavior trained on old data may continue recommending products that are no longer in demand. Regular updates with fresh data ensure the model adapts to these changes, improving its accuracy and relevance over time.
Training AI models with synthetic data helps prepare them for rare or unexpected scenarios. These circumstances are known as edge cases, which they might not frequently encounter in real-world data. By simulating these extreme situations, synthetic data enables AI systems to handle unpredictable events. For example, an AI solution used in autonomous vehicles can be trained with synthetic data to handle rare road accidents or unusual weather conditions.
Contextual awareness is the key to an AI system that genuinely works in the real world. Without it, even the most sophisticated models risk making flawed decisions. Poorly trained AI models can misinterpret situations, reinforce biases, or struggle in unpredictable environments.
At Objectways, we believe in ethical and responsible AI, and that starts with proper data and training. Our expert data labeling and annotation services help AI models learn from diverse, high-quality datasets – reducing bias and improving accuracy. Want to build AI solutions that make smarter, context-aware decisions? Contact us today.


Factories used to run with people and machines working together, guided by fixed schedules, checklists, and workers’ experience. When something went wrong, teams would step...

With innovations like ChatGPT gaining in popularity, artificial intelligence (AI) is now a part of daily life for millions of people worldwide. It is used in sectors...
