Artificial intelligence (AI) solutions are quickly becoming a key part of our society, and data labeling plays a major role in their success. Data labeling, also called annotation, refers to adding tags or labels to data like images, text, or audio so AI systems can learn to recognize patterns and make accurate predictions.
High-quality data labeling leads to exceptional AI systems, similar to skilled teachers shaping outstanding students. Unfortunately, the reverse is also true. Any oversight or errors in data annotation and labeling can have a huge impact on resulting AI models, and it happens more often than you would think. In fact, research shows that 85% of AI projects don’t succeed, primarily because of issues with data quality.
If you’re looking to build an AI solution, high-quality data annotations are the secret ingredient for success. However, curating such annotations isn’t as straightforward as it sounds – and that’s where Objectways can step in to help. Objectways has been a trusted expert in data labeling for over five years. We’ve labeled over 100 million data points so far, helping businesses create better AI systems.
In this article, we’ll dive into different types of data annotations, their key features, and applications. Let’s get started!
Data annotation is a vital step in developing an AI model. It involves using labels to convert raw data into information and context for AI systems. Without proper data labels, training an AI model is like giving a student practice test questions without any explanations for the answers. Data labeling is especially critical for supervised machine learning models, which depend on labeled data to learn. In contrast, unsupervised machine learning can work with unlabeled data, discovering patterns on its own.
Let’s take one branch of AI, computer vision, as an example. Think about teaching a kid what a cat is. You’d show them pictures of cats and say, ‘This is a cat,’ until they get the hang of it. Training an AI model to recognize cats works the same way – you give it multiple images labeled as ‘cat’ or ‘not cat.’ With enough examples, the AI model can start recognizing cats in new, unlabeled images.
It’s important to understand that the AI model doesn’t just look at the whole picture – it also picks up on specific features. Just like humans can recognize a cat even if only part of it is visible, AI learns to detect pointed ears, whiskers, fur texture, and eye shape. It can even tell the difference between a real cat and a person wearing cat-ear accessories by analyzing these details in context. By analyzing key features rather than relying on the entire image, AI models can make more accurate and intelligent predictions.
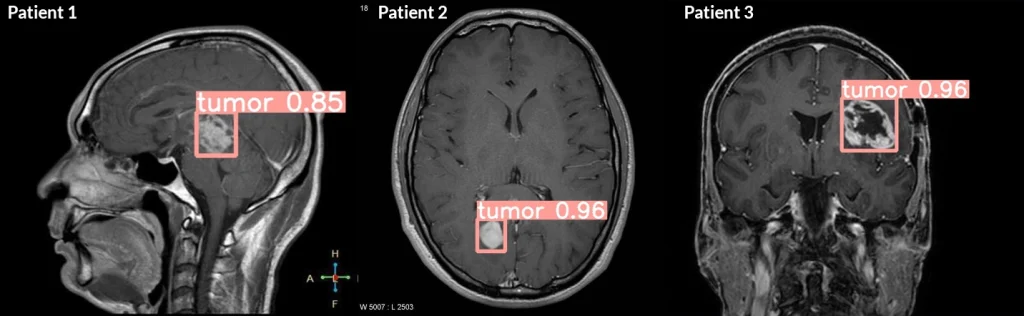
An interesting application of this is AI in healthcare. Computer vision models can be used to find tumors or bone fractures by training them on well-labeled X-rays and MRI scans. For instance, doctors and annotators can label regions on scans that show abnormalities, like fractures or tumors, giving the computer vision model clear examples of what to identify. Over time, the computer vision model becomes capable of spotting these issues in new scans, and doctors can use the model to catch health concerns faster and improve patient outcomes.
No two students learn the same way, so you can’t teach them all with a one-size-fits-all approach. In the same way, how we annotate data changes depending on the type of application and the kind of data we’re working with. Let’s take a closer look at the different types of data annotation methods and how they are used.
Computer vision is a subfield of AI focused on analyzing visual inputs like images and videos. In computer vision, data annotation usually involves tagging images and videos and linking each tag to a specific object or category.
Here are some different types of data annotations that are used for various computer vision techniques:

High-quality labeled text data helps build reliable NLP applications. NLP is an AI technology that helps machines understand and process human language, whether it’s written or spoken.
To train NLP models, textual data needs to be annotated with tags or categories that provide context, like identifying parts of speech, sentiment, or key entities such as names and locations. Textual data annotation forms a substantial part of creating tools like chatbots, which need well-labeled data to understand user questions and respond appropriately.
Other NLP use cases that require textual data annotation include:
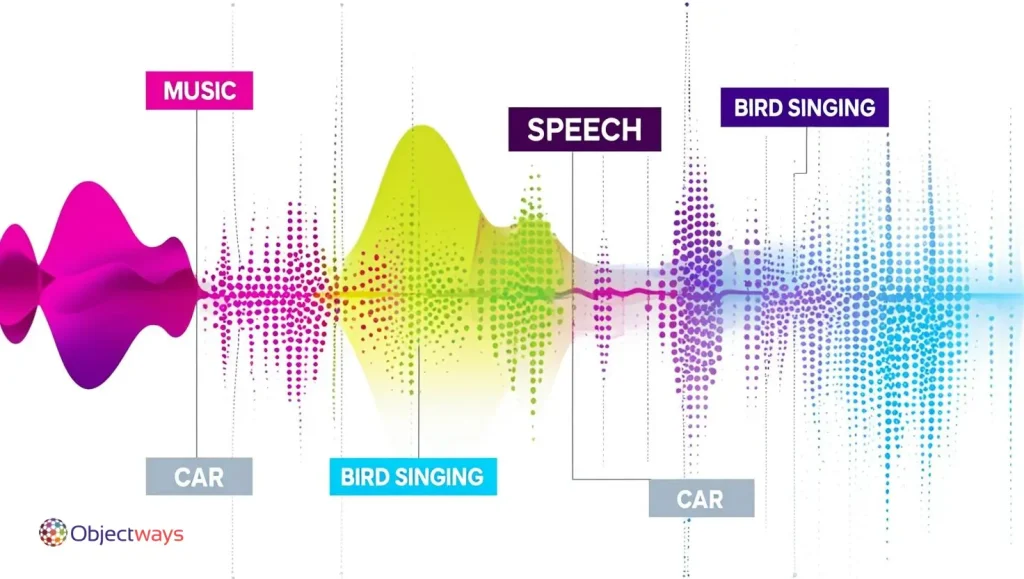
Audio annotation is the process of adding labels to audio recordings to help AI models understand and process them better. These recordings might include speech, music, animal sounds, or background noise. The labels provide important context, like identifying who is speaking, what’s being said, or when certain sounds occur.
For example, annotators might mark specific timestamps, label different speakers, or tag types of sounds. Audio annotation is especially useful for training AI systems, like virtual assistants, that need to accurately respond to voice commands. It’s also important in call centers, where AI helps analyze conversations to improve customer service.
The world is more connected than ever, and companies like Google, Microsoft, and Meta are creating advanced AI models, including large language models (LLMs), with multilingual capabilities.
These models are being built to break down language barriers and work seamlessly across different languages. A key part of training LLMs for language translation is annotating multilingual data. Typically, it involves adding tags or metadata to text to provide context, helping the AI model understand the nuances of different languages.
Consider teaching an AI model to translate between English and Spanish. Annotators might mark whether a phrase is formal or casual, or explain idiomatic expressions. They could even tag when “thank you” should be translated as “gracias” or “muchas gracias,” depending on the context. These kinds of details help the AI provide more accurate, natural, and culturally appropriate translations.
Next, let’s take a look at a couple of ways data labeling is used in everyday applications.
Did you know that the last time you watched a movie with subtitles, data labeling probably helped make that happen? One common use of data labeling is in creating subtitles for videos. Labeling subtitles for multiple movies or shows, especially in different languages, can be time-consuming.
Plus, human translators can make mistakes. Nowadays, media companies are using AI technologies like NLP and Generative AI to solve this. With the right data labeling, AI models can automatically generate subtitles in many languages, saving time and reducing errors.
Another fascinating application of data labeling is in computer vision for the defense industry. Here, data labeling can help train AI models to analyze visual data from drones or satellite images. These models can identify potential threats, such as suspicious vehicles or unusual activity in surveillance footage. With properly labeled data, the AI model can learn to spot these threats more accurately and quickly.
Despite seeming simple, data labeling comes with challenges like data security. Of late, many new laws and regulations have been put in place to handle the issue of data security carefully.
Complying with data privacy regulations like the General Data Protection Regulation (GDPR) and Data Protection Agreements (DPA) is non-negotiable. Strict measures are required to prevent sensitive information from being accessed on unsecured devices, shared in unverified locations, or exposed in public areas.
To mitigate these risks, Objectways implements rigorous security measures, including no-phone policies, access-controlled clean rooms, 24/7 surveillance, and restricted internet access to prevent unauthorized data extraction. Downloads and screenshots are also disabled for data privacy purposes. These precautions guarantee that sensitive data remains fully protected during the annotation process.
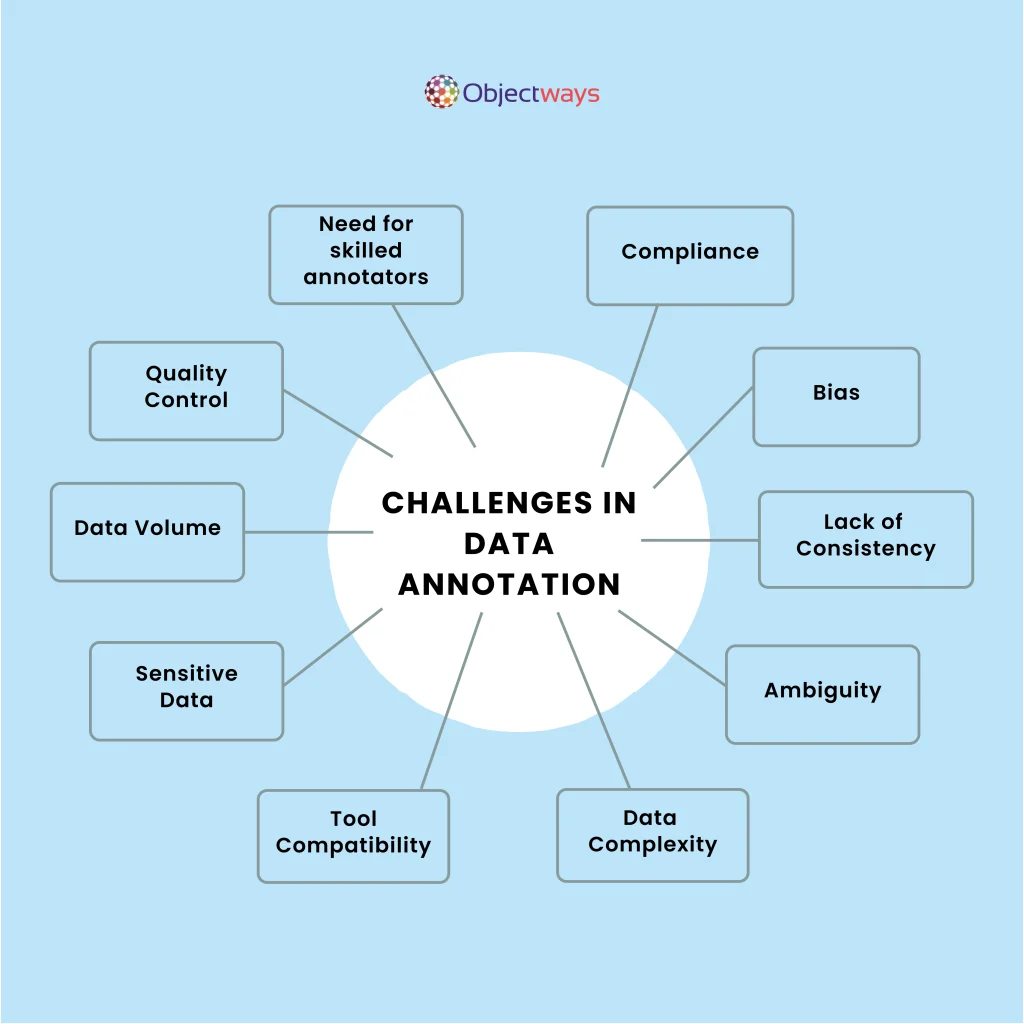
On top of that, annotations need to consistently meet quality standards. This means that annotators have to understand the context of the data and think about tagging data to ensure high model accuracy. A combination of skilled annotators, clear guidelines, and regular quality checks are key.
Meanwhile, balancing speed and quality for large-scale annotation projects is also a major limitation. Oftentimes, you need high volumes of labeled data to quickly develop AI systems. However, rushing the process can result in poor accuracy, making the final AI system less reliable. To get this balance right, there needs to be streamlined workflows, advanced tools, and a skilled workforce to produce top-notch annotations.
The challenges related to data annotation may seem daunting, but at Objectways, we can handle them and let you focus on other aspects of your AI solution. Our team of highly skilled data annotators and experts can work on even the most difficult annotation tasks.
They are specifically trained to annotate data with great precision. Even if you have unique requirements, we can customize our labeling methods to meet your goals, ensuring the data is perfect for your use case.
Here are some more reasons to choose Objectways for data labeling:
You might be wondering – what exactly sets apart Objectways’ reliable data annotations? Here’s a quick glance at some key factors that make our data annotations as effective as possible:
We’ve discussed how data labeling is essential for turning raw data into something valuable that AI solutions can use to make accurate predictions. Whether it’s labeling images or text, the right annotation approach makes it possible for AI models to perform well across different tasks and industries.
At Objectways, we make data labeling simple and reliable with a team of skilled experts, flexible services, and thorough quality checks. We help businesses build AI systems that are accurate, efficient, and ready to tackle real-world challenges.
Looking to bring your AI solutions to life? Contact Objectways today, and let’s talk about how our data labeling solutions can support your success!

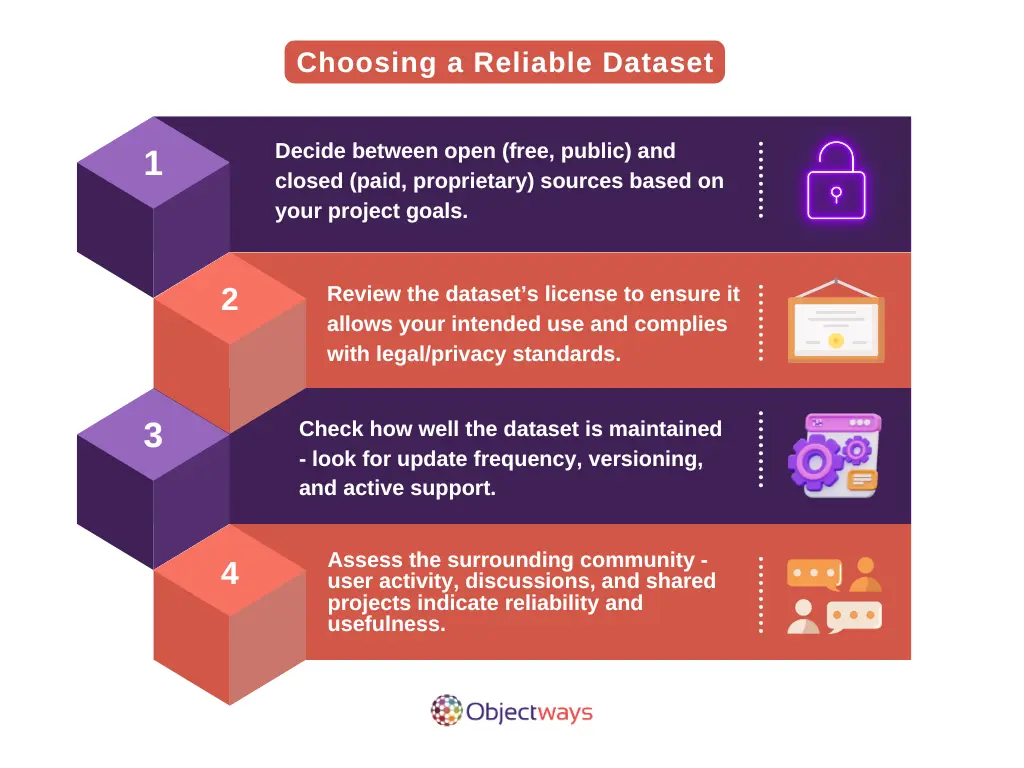
Choosing the right dataset is one of the most important steps in building an object detection model that performs well. Just like you need a...
Choosing a data labeling tool for your AI project is a lot like picking the right equipment for a construction job. You wouldn’t rely on light-duty tools...
