When building AI models, especially in fields like healthcare, accuracy is key because even small mistakes can lead to serious consequences like misdiagnoses or incorrect prescriptions. High-quality, accurately labeled data is the backbone of a reliable AI model – any error in the data can directly affect the model’s performance. So, how can we make sure that data labelers (also known as annotators) and evaluators maintain both fairness and consistency? That’s where inter-rater reliability (IRR) comes in.
Simply put, IRR is a way to measure agreement between different people (raters) rating the same thing (in this case, data labeling). It checks if they are making similar judgments instead of random or biased decisions. IRR can be used to check if different data labellers are labeling the same data in a consistent way, making sure the results of the final AI model are fair and reliable.
Inter rater reliability is usually expressed as a number, often a percentage (e.g., 90% agreement), or a statistical measure. A higher value means better agreement between raters. In this article, we’ll take a closer look at what inter-rater reliability is and why it matters for AI and data labeling.
Inter-rater reliability checks if different people evaluating the same thing produce similar results – for example, when multiple annotators label data for AI training. In contrast, intra-rater reliability measures whether the same person gives consistent ratings over time.
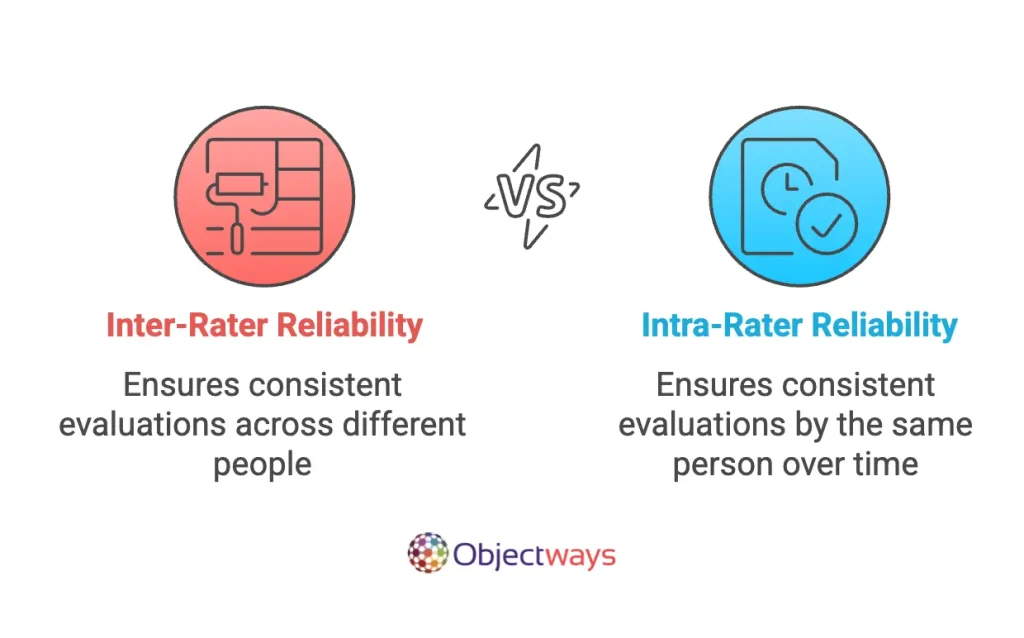
Inter-rater reliability is especially useful in the field of research since it can ensure that study results are fair and trustworthy. For example, in areas like qualitative research, where opinions and interpretations matter, IRR is crucial. If different experts agree on the results, it shows that the findings are not just one person’s opinion but a collaborative outcome with more solid results.
Also, when multiple people are involved in a study, inter-rater reliability helps keep things consistent, so the results aren’t affected by differences in how each person observes or judges the data.
With respect to data labeling, IRR measures how consistently different data labelers label the same set of training data. If all the labelers mostly agree on the same label for a piece of data, the dataset is reliable; if they don’t, it may have inconsistencies that affect its overall quality. Think of it like a group of painters working on a mural – if they all follow the same plan, the mural looks unified; if they don’t, the final result can look messy.
You might wonder if metrics like inter-rater reliability are really necessary. Let’s break down why they are so important.
Data labeling, or data annotation, involves adding tags to raw data, such as images, to help AI models recognize patterns. These labels highlight key features in the data, making it possible for AI models to learn and make accurate predictions on new, unlabeled information. Ultimately, the better the labeling, the more reliable and precise the AI’s results.
However, creating reliable AI models comes with certain challenges. One major issue is the difference in interpretations among annotators. When people see the same data differently, inconsistencies and bias can creep in. Some tasks, like labeling medical images or legal documents, require expert knowledge, and without it, errors can occur. Also, labeling large datasets is time-consuming and resource-intensive, and as more people contribute, maintaining consistency becomes even more complicated.
That’s exactly why high inter-rater reliability (IRR) is so important.
Next, let’s explore some of the methods used to measure inter-rater reliability:
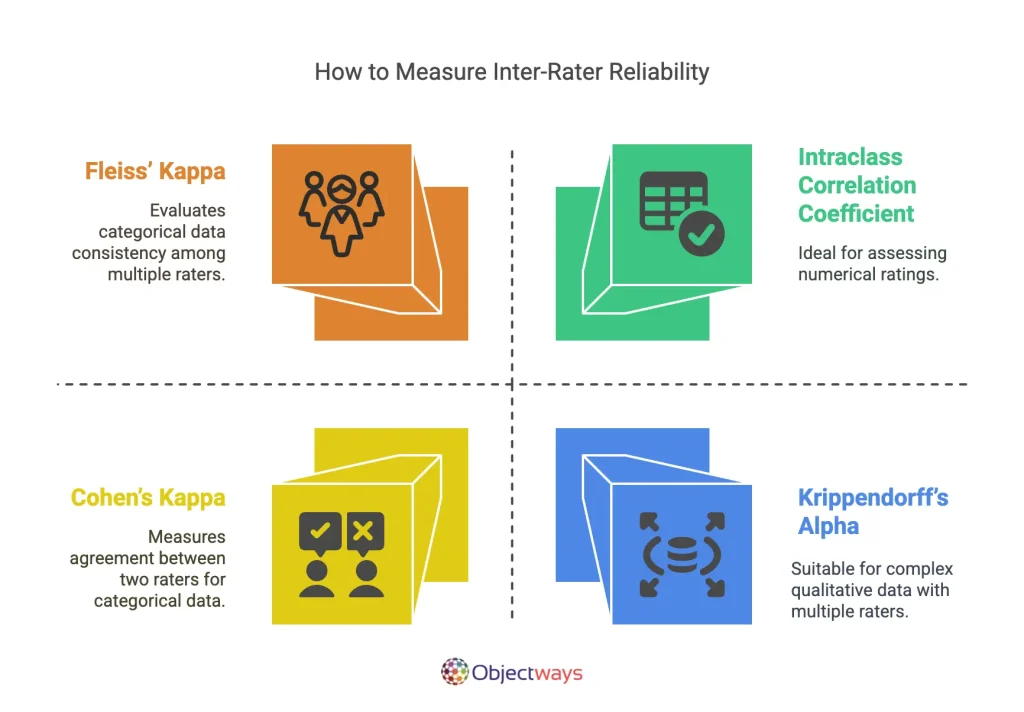
Now that we’ve discussed how to measure IRR, let’s go through an example to get a better idea of how low IRR affects an AI model.
Take, for instance, an AI solution designed to recognize animals in photos – specifically, cats and dogs. To train this system, a team of data labelers reviews thousands of images and assigns a label to each one. When most labelers agree on what each image shows, the training data is consistent and reliable, leading to a high IRR value. For example, if 90% of the labelers correctly identify an image as a cat based on clear features like pointed ears and whiskers, the AI model learns to recognize cats accurately.
Now, imagine a scenario where there’s a low IRR. Consider an image where the animal is partially obscured by shadows. One labeler might correctly identify the animal as a cat by focusing on visible features. At the same time, another might mistakenly label it as a dog because of misinterpreting the posture or background. In another case, if one labeler labels a small, fluffy dog as a cat and another labels a similar image correctly as a dog, the dataset becomes inconsistent.
This inconsistency in labeling sends mixed signals to the AI model during training. As a result, the model might develop inaccurate or biased patterns, leading to errors like misclassifying cats as dogs or failing to recognize certain breeds entirely. Overall, low IRR compromises the quality of the training data, forcing developers to spend extra time and resources cleaning and relabeling the data to improve the model’s accuracy.
Having understood the importance of IRR, an interesting question that follows is: how can we annotate data while aiming for high inter-rater reliability? Here are some strategies to help labelers work together more seamlessly while creating consistent data that leads to more accurate AI predictions:
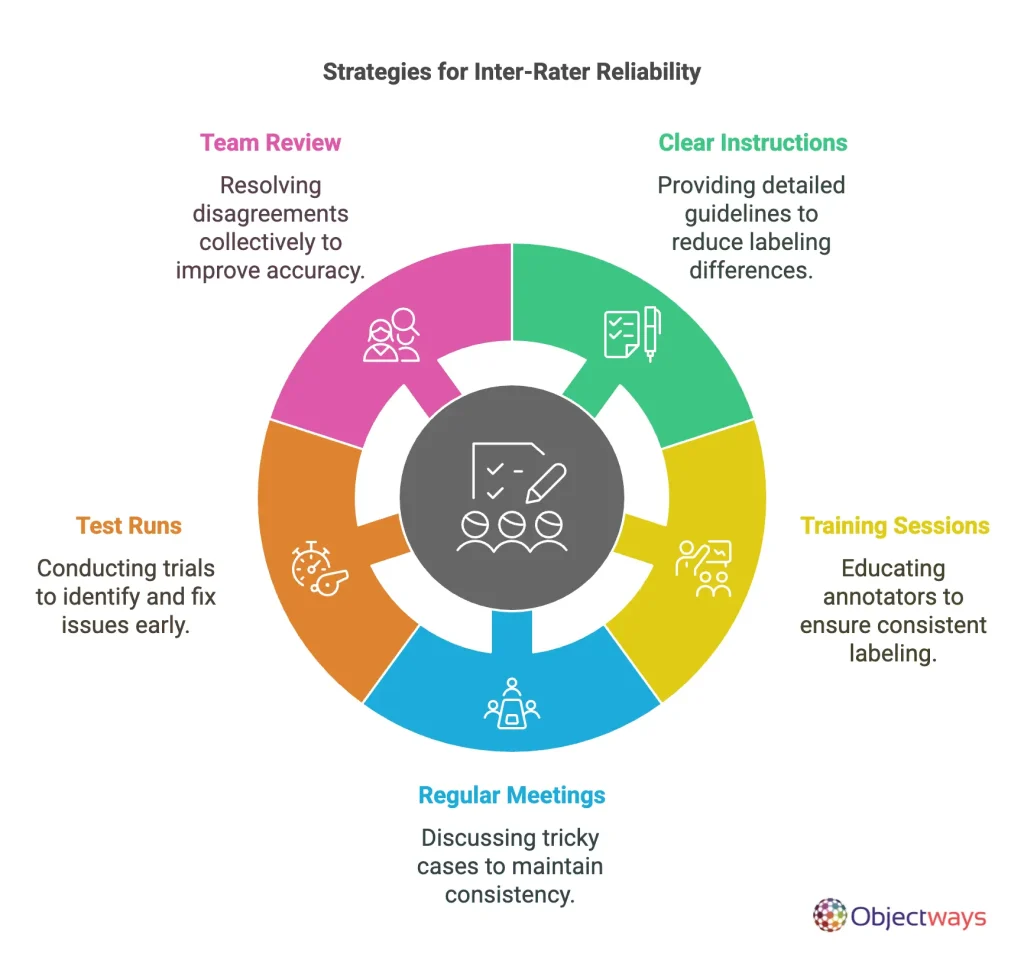
Inter-rater reliability is a key factor in building robust AI applications across different industries by supporting the creation of consistent and unbiased data. Next, we’ll explore a few use cases and see why IRR is essential for reliable AI outcomes in these cases.
With the number of hours that we spend online, making the internet and social media a safe place is a top priority. A recent survey reveals that 79% of respondents believe that incitements to violence should be removed from social media.
In response to this, we are seeing content moderation systems increasingly rely on AI to sift through vast amounts of user content and quickly flag potential issues. However, for AI to make fair and accurate decisions, it needs to be trained on high-quality data.
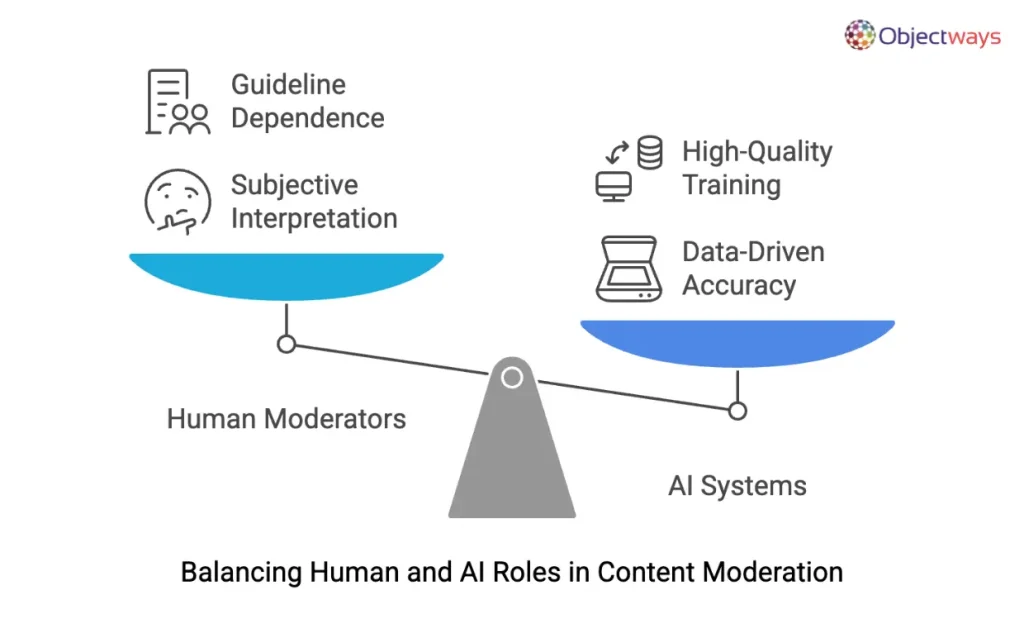
This is where inter-rater reliability (IRR) can become a concern. For example, if one moderator sees a comment as humorous while another finds it offensive, the inconsistency can confuse the AI model. Clear guidelines and regular calibration sessions help align moderators to be on the same page.
AI can be used to analyze legal documents and review contracts with impressive accuracy. Cutting-edge technology can help legal professionals extract key information, identify potential risks, and streamline the review process. In fact, a survey by the American Bar Association found that 10% of legal professionals now use AI for tasks like document analysis in litigation. There is a clear, growing market for these technologies in the legal field.
However, legal documents are filled with nuanced language and complex structures that can lead to different interpretations among annotators. This room for misinterpretations creates variability in the training data, which can confuse the AI model and affect its performance. When the data isn’t labeled consistently, the AI model may struggle to accurately identify important clauses. Data labeling guidelines with inter-rater reliability kept in mind can eliminate such limitations.
At Objectways, we take a hands-on approach to data labeling to guarantee both accuracy and consistency. Our team of over 2,200 trained professionals specializes in labeling a variety of data types – text, audio, images, LiDAR, and video – with a deep understanding of the industry-specific context.
Unlike crowdsourced labeling, where different people might tag data inconsistently, our in-house experts follow strict guidelines to keep everything uniform. Whether it’s labeling speech for voice assistants, marking objects in images for self-driving cars, or organizing medical data, our team focuses on maintaining high inter-rater reliability and supporting better outcomes for your AI projects.
High inter-rater reliability is key to data being labeled more consistently, which is essential for training accurate and unbiased AI models. Clear guidelines, expert reviews, and regular training help keep labeling consistent.
At Objectways, our team of expert data labelers delivers precise annotations that reduce errors and boost AI performance. Whether it’s for content moderation or legal document analysis, better labeling leads to smarter, more reliable AI.
Looking for someone to support you on your AI adventure? Reach out to us today.

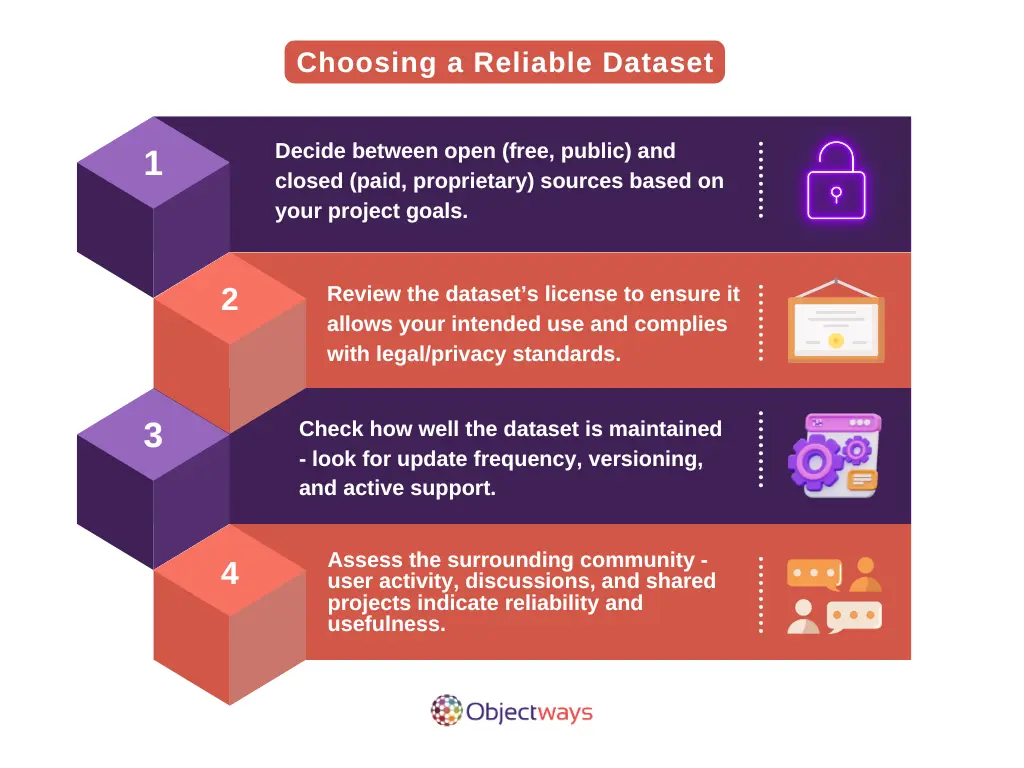
Choosing the right dataset is one of the most important steps in building an object detection model that performs well. Just like you need a...
Choosing a data labeling tool for your AI project is a lot like picking the right equipment for a construction job. You wouldn’t rely on light-duty tools...
